Ch. 16 The Molecular Basis of Inheritance Dynamic Study Module
One strand of a DNA molecule has the base sequence 5'-ATAGGT-3'. The complementary base sequence on the other strand of DNA will be 3'-__________-5'.
- ATAGGT
- TGGAUA
- TGGATA
- TATCCA
- UAUCCA
TATCCA
Ex.
One strand of a DNA molecule has the base sequence 5'-ATAGGT-3'. The complementary base sequence on the other strand of DNA will be 3'-TATCCA-5'.
This question requires you to know how bases pair in DNA. A pairs with T and G pairs with C. Uracil (U) is a component of RNA but not DNA.
The two sugar-phosphate strands that form the rungs of a DNA double helix are joined to each other through __________.
- ionic bonds between guanine and cytosine
- covalent bonds between carbon atoms in deoxyribose molecules
- covalent bonds between nitrogen atoms in adenine and in thymine
- 5' deoxyribose and phosphate bonds
- hydrogen bonds between nucleotide bases
hydrogen bonds between nucleotide bases
Ex.
The two sugar-phosphate strands that form the rungs of a DNA double helix are joined to each other through hydrogen bonds between nucleotide bases.
DNA has the shape of a twisted ladder, where the “rungs” are the base pairs joined by hydrogen bonds, and the sides of the ladder or “backbone” are the phosphate-sugar groups joined by covalent bonds. Deoxyribose is the name for the sugar, not a type of bond.
The two sugar-phosphate strands that form the rungs of a DNA double helix are joined to each other through hydrogen bonds between nucleotide bases.
DNA has the shape of a twisted ladder, where the “rungs” are the base pairs joined by hydrogen bonds, and the sides of the ladder or “backbone” are the phosphate-sugar groups joined by covalent bonds. Deoxyribose is the name for the sugar, not a type of bond.
Replication of the lagging strand of DNA is accomplished by repeatedly making __________ followed by 1,000–2,000 nucleotide segments called __________.
- long RNA primers; Okazaki segments
- short DNA primers; Watson segments
- short primers; Okazaki segments
- short RNA primers; Okazaki fragments
- DNA ligase; Watson fragments
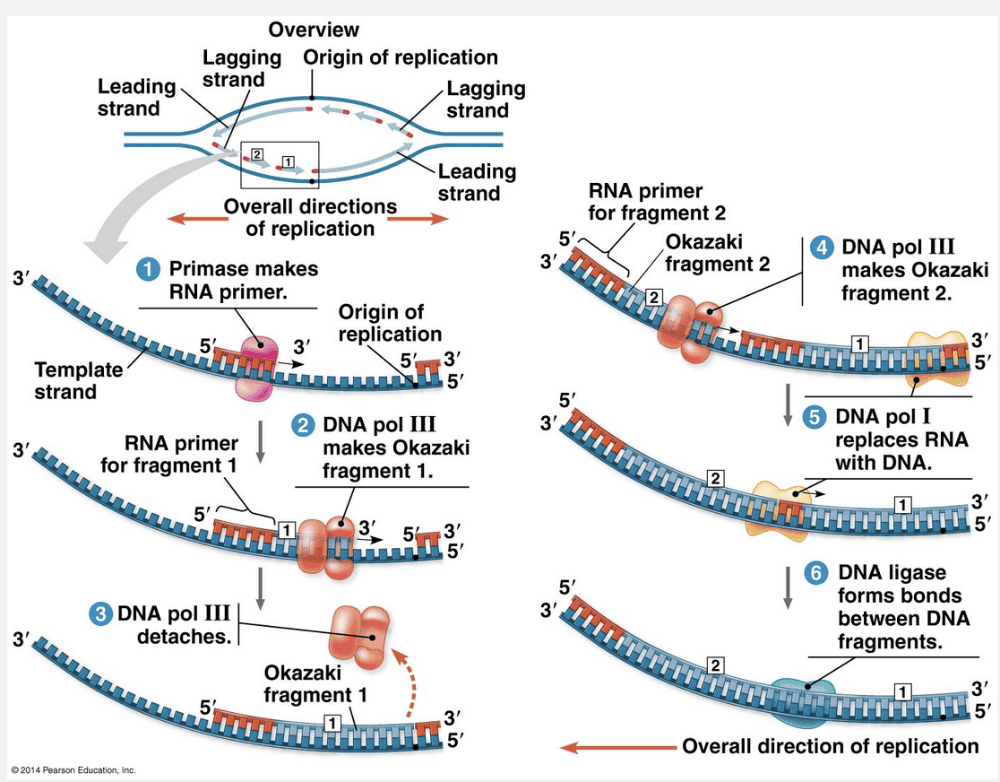
short RNA primers; Okazaki fragments
Ex.
Replication of the lagging strand of DNA is accomplished by repeatedly making short RNA primers followed by 1,000–2,000 nucleotide segments called Okazaki fragments.
To elongate the lagging strand of DNA in the mandatory 5ꞌ → 3ꞌ direction, DNA polymerase must work alongside the other template strand in the direction away from the replication fork. In contrast to the leading strand, which elongates continuously, the lagging strand is synthesized discontinuously as a series of segments. These segments of the lagging strand are called Okazaki fragments, after the Japanese scientist who discovered them. The fragments are about 1,000–2,000 nucleotides long in E. coli and 100–200 nucleotides long in eukaryotes. The figure below illustrates the steps in the synthesis of the lagging strand at one fork. Whereas only one primer is required on the leading strand, each Okazaki fragment on the lagging strand must be primed separately.
“Short DNA primers; Watson segments” is incorrect because the primer is a short RNA strand that allows the DNA polymerase to make longer Okazaki fragments. “Long RNA primers; Okazaki segments” is incorrect because the RNA primers are short and the segments of DNA are called Okazaki fragments. “DNA ligase; Watson fragments” is incorrect because DNA ligase forms a bond between two Okazaki fragments after the RNA primer has been removed. “Short primers; Okazaki segments” is incorrect because the primers are RNA, not DNA, and the segments of DNA are called Okazaki fragments.
In bacterial DNA replication of the lagging strand, __________ is required for the synthesis of a new DNA strand whereas __________ is required for removing the RNA primer and replacing it with DNA nucleotides.
- DNA ligase; DNA polymerase I
- DNA polymerase I; DNA ligase
- DNA polymerase III; DNA ligase
- DNA polymerase III; DNA polymerase I
- DNA polymerase I; DNA polymerase III
DNA polymerase III; DNA polymerase I
Ex.
In bacterial DNA replication of the lagging strand, DNA polymerase III is required for the synthesis of a new DNA strand whereas DNA polymerase I is required for removing the RNA primer and replacing it with DNA nucleotides.
DNA polymerase III can synthesize a complementary strand continuously by elongating the new DNA in the mandatory 5ꞌ → 3ꞌ direction. DNA polymerase III remains in the replication fork on that template strand and continuously adds nucleotides to the new complementary strand as the fork progresses. After DNA polymerase III forms an Okazaki fragment, another DNA polymerase, DNA polymerase I, replaces the RNA nucleotides of the adjacent primer with DNA nucleotides. But DNA polymerase I cannot join the final nucleotide of this replacement DNA segment to the first DNA nucleotide of the adjacent Okazaki fragment. Another enzyme, DNA ligase, accomplishes this task, joining the sugar-phosphate backbones of all the Okazaki fragments into a continuous DNA strand.
“DNA polymerase I; DNA polymerase III” is incorrect because DNA polymerase III synthesizes the new strand, and DNA polymerase I removes the RNA primer and replaces it with DNA nucleotides. “DNA polymerase III; DNA ligase” is incorrect because DNA ligase forms a bond between two Okazaki fragments after the RNA primer has been removed. “DNA polymerase I; DNA ligase” is incorrect because DNA polymerase I removes the RNA primer and replaces it with DNA nucleotides, and then DNA ligase forms a bond between two Okazaki fragments after the RNA primer has been removed. “DNA ligase; DNA polymerase I” is incorrect because DNA ligase forms a bond between two Okazaki fragments after DNA polymerase I removes the RNA primer and replaces it with DNA nucleotides.
The role of DNA polymerases in DNA replication is to __________.
- link together short strands of DNA
- separate the two strands of DNA
- attach free nucleotides to the new DNA strand
- synthesize an RNA primer to initiate DNA strand synthesis
- All of the listed responses are correct.
attach free nucleotides to the new DNA strand
Ex.
The role of DNA polymerases in DNA replication is to attach free nucleotides to the new DNA strand.
DNA polymerases are the enzymes that catalyze the addition of nucleotides to a preexisting chain. Primases synthesize the RNA primer that initiates DNA synthesis. DNA ligase is the enzyme that joins the Okazaki fragments together on the lagging strand. Helicase separates the two DNA strands prior to replication.
In DNA replication, the next nucleotide is incorporated into the growing polymer at the __________ of the molecule by an enzyme called __________.
- 3ꞌ (phosphate) end; RNA polymerase
- 3ꞌ (hydroxyl) end; DNA polymerase
- 3ꞌ (hydroxyl) end; topoisomerase
- 5ꞌ (phosphate) end; DNA polymerase
- 5ꞌ (hydroxyl) end; RNA polymerase
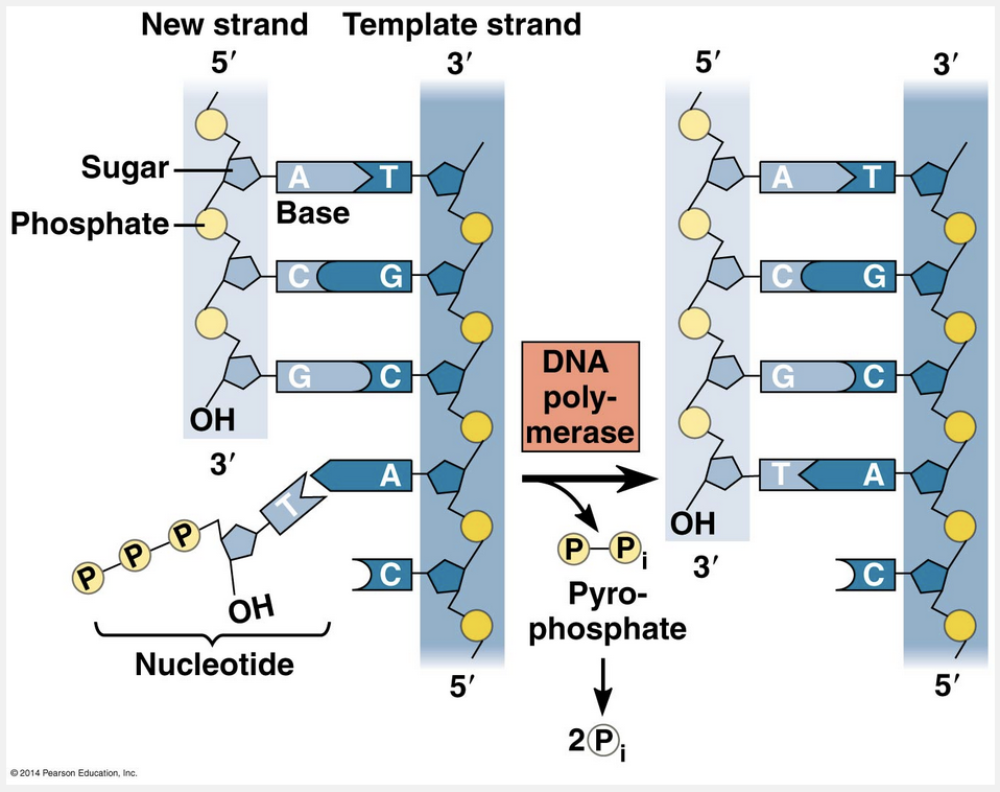
3ꞌ (hydroxyl) end; DNA polymerase
Ex.
In DNA replication, the next nucleotide is incorporated into the growing polymer at the 3ꞌ (hydroxyl) end of the molecule by an enzyme called DNA polymerase.
Enzymes called DNA polymerases catalyze the synthesis of new DNA by adding nucleotides to a preexisting chain. Because of their structure, DNA polymerases can add nucleotides only to the free 3ꞌ end of a primer or growing DNA strand, never to the 5ꞌ end. Thus, a new DNA strand can elongate only in the 5ꞌ → 3ꞌ direction.
“5ꞌ (hydroxyl) end; RNA polymerase” is incorrect because the enzyme that synthesizes DNA is called DNA polymerase. “3ꞌ (phosphate) end; RNA polymerase” is incorrect because the 3ꞌ end always has a free hydroxyl group, and the enzyme that synthesizes DNA is called DNA polymerase. “5ꞌ (phosphate) end; DNA polymerase” is incorrect because DNA polymerases can add nucleotides only to the free 3ꞌ end of a primer or growing DNA strand, never to the 5ꞌ end. “3ꞌ (hydroxyl) end; topoisomerase” is incorrect because the enzyme that synthesizes DNA is called DNA polymerase.
When __________ form after an exposure to ultraviolet (UV) light, a __________ can remove the damaged nucleotides and replace them with normal nucleotides.
- thymidine dimers; nucleotide excision repair enzyme
- cytosine dimers; nucleotide excision repair enzyme
- guanosine dimers; nucleotide incision repair enzyme
- guanosine dimers; nucleotide excision repair enzyme
- thymidine dimers; nucleotide incision repair enzyme
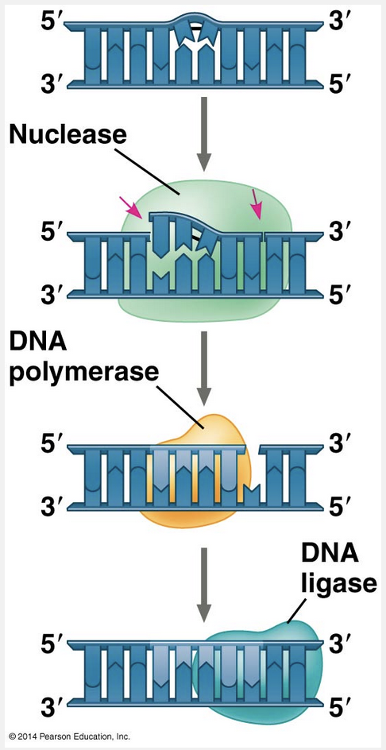
thymidine dimers; nucleotide excision repair enzyme
Ex.
When thymidine dimers form after an exposure to ultraviolet (UV) light, a nucleotide excision repair enzyme can remove the damaged nucleotides and replace them with normal nucleotides.
Most cellular systems for repairing incorrectly paired nucleotides, whether due to DNA damage or to replication errors, use a mechanism that takes advantage of the base-paired structure of DNA. In many cases, a segment of the strand containing the damage is cut out (excised) by a DNA-cutting enzyme—a nuclease—and the resulting gap is then filled in with nucleotides, using the undamaged strand as a template. The enzymes involved in filling the gap are DNA polymerase and DNA ligase. One such DNA repair system is called nucleotide excision repair. An important function of the DNA repair enzymes in our skin cells is to repair genetic damage caused by the ultraviolet rays of sunlight. One type of damage, shown in the figure here, is the covalent linking of thymine bases that are adjacent on a DNA strand. Such thymine dimers cause the DNA to buckle and interfere with DNA replication. The importance of repairing this kind of damage is underscored by the existence of a disorder called xeroderma pigmentosum, which in most cases is caused by an inherited defect in a nucleotide excision repair enzyme. Individuals with this disorder are hypersensitive to sunlight, and mutations in their skin cells caused by ultraviolet light are left uncorrected, resulting in skin cancer.
“Guanosine dimers; nucleotide excision repair enzyme” and “cytosine dimers; nucleotide excision repair enzyme” are incorrect because UV exposure causes two thymine bases that are next to each other on the same DNA strand to covalently link and form a kink that interferes with DNA replication. “Thymidine dimers; nucleotide incision repair enzyme” is incorrect because the repair enzyme is called a nucleotide excision repair enzyme. “Guanosine dimers; nucleotide incision repair enzyme” is incorrect because UV exposure causes two thymine bases that are next to each other on the same DNA strand to covalently link and form a kink that interferes with DNA replication; also, the repair enzyme is called a nucleotide excision repair enzyme.
The overall error rate in the completed DNA molecule is approximately __________.
- 1 error per 10,000,000,000 nucleotides
- 1 error per 1,000,000 nucleotides
- 1 error per 100 nucleotides
- 1 error per 1,000 nucleotides
- 1 error per 1,000,000,000 nucleotides
1 error per 10,000,000,000 nucleotides
Ex.
The overall error rate in the completed DNA molecule is approximately 1 error per 10,000,000,000 nucleotides or 1010 nucleotides.
DNA polymerase adds nucleotides to the __________ of the leading strands, and to the __________ of the lagging strands (Okazaki fragments).
- 3' end; 5' end
- 5' end; 3' end
- 5' end; 5' end
- sugar group; phosphate group
- 3' end; 3' end
3' end; 3' end
Ex.
DNA polymerase adds nucleotides to the 3' end of the leading strands, and to the 3' end of the lagging strands (Okazaki fragments).
DNA polymerase can only add nucleotides to the 3’ end of a growing strand, regardless of whether it is the leading or the lagging strand.
Evidence to support that DNA strands run antiparallel to each other includes all of the following except __________.
- that the sugar-phosphate backbones are to the inside of the molecule
- X-ray measurement data
- Chargaff’s rules
- that the nitrogenous bases are on the inside
- hydrogen bonding interactions
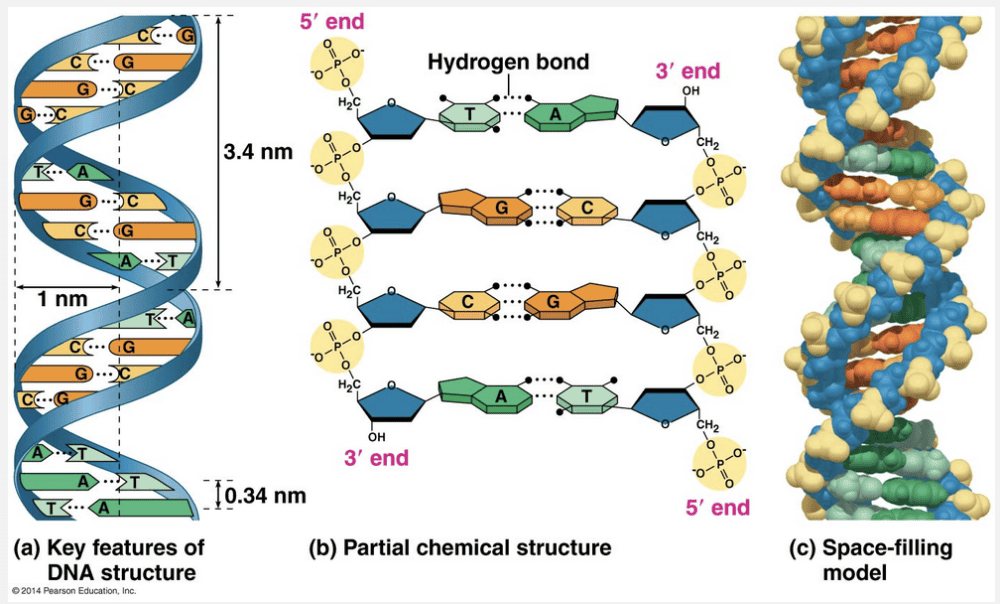
that the sugar-phosphate backbones are to the inside of the molecule
Ex.
Evidence to support that DNA strands run antiparallel to each other includes all of the following except that the sugar-phosphate backbones are to the inside of the molecule.
Franklin’s arrangement of the DNA molecule appealed to Watson and Crick because it put the relatively hydrophobic nitrogenous bases in the molecule’s interior, away from the surrounding aqueous solution. In addition, the negatively charged phosphate groups aren’t forced together in the interior of the molecule. Watson and Crick began building models of a double helix that would conform to the X-ray measurements and what was then known about the chemistry of DNA, including Chargaff’s rule of base equivalences. Having also read an unpublished annual report summarizing Franklin’s work, they knew of her conclusion that the sugar-phosphate backbones are on the outside of the DNA molecule, contrary to Watson and Crick’s working model. Watson then constructed such a model, shown in the lower photo here. In this model, the two sugar-phosphate backbones are antiparallel—that is, their subunits run in opposite directions.
“Chargaff’s rules,” “X-ray measurement data,” “hydrogen bonding interactions,” and “that the nitrogenous bases are on the inside” are evidence supporting that DNA strands run in antiparallel directions. Since this is an except question, all of these responses are incorrect.
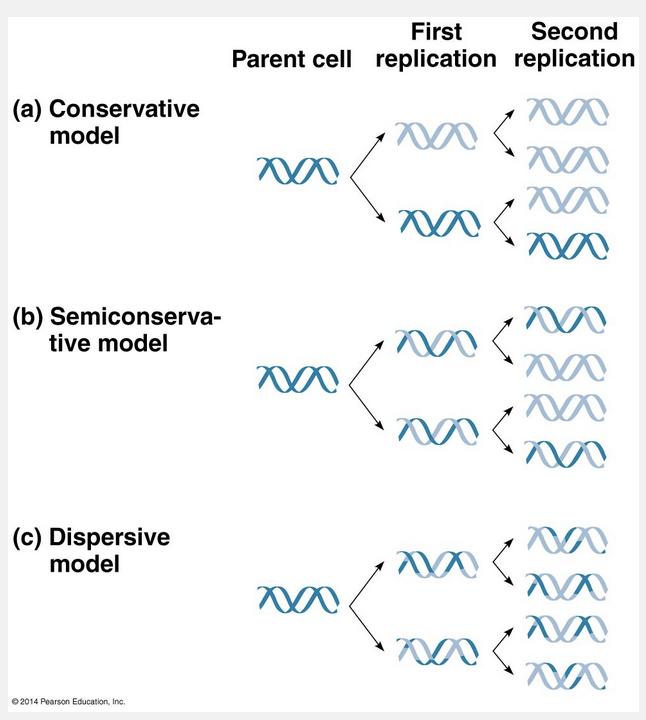
Of the three alternative models of DNA replication, which are the __________ models, the one that explains how DNA replicates is the __________ model.
- conservative, nonconservative, and dispersive; dispersive
- conservative, semiconservative, and dispersive; conservative
- conservative, nonconservative, and dispersive; nonconservative
- conservative, semiconservative, and dispersive; semiconservative
- conservative, semiconservative, and dispersive; dispersive
conservative, semiconservative, and dispersive; semiconservative
Ex.
Of the three alternative models of DNA replication, which are the conservative, semiconservative, and dispersive models, the one that explains how DNA replicates is the semiconservative model.
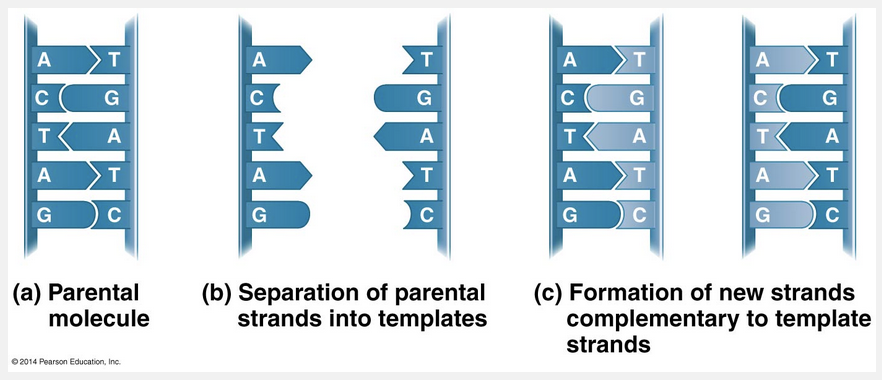
This figure illustrates Watson and Crick’s basic idea. To make it easier to follow, we show only a short section of the double helix in untwisted form. Notice that if you cover one of the two DNA strands in the second part of the figure, you can still determine its linear sequence of nucleotides by referring to the uncovered strand and applying the base-pairing rules. The two strands are complementary, and each stores the information necessary to reconstruct the other. When a cell copies a DNA molecule, each strand serves as a template for ordering nucleotides into a new complementary strand. Nucleotides line up along the template strand according to the base-pairing rules and are linked to form the new strands. Where there was one double-stranded DNA molecule at the beginning of the process, there are soon two, each an exact replica of the “parental” molecule. The copying mechanism is analogous to using a photographic negative to make a positive image, which can in turn be used to make another negative, and so on. This model of DNA replication remained untested for several years following publication of the DNA structure. The requisite experiments were simple in concept but difficult to perform. Watson and Crick’s model predicts that when a double helix replicates, each of the two daughter molecules will have one old strand from the parental molecule and one newly made strand. This semiconservative model can be distinguished from a conservative model of replication, in which the two parental strands somehow come back together after the process (that is, the parental molecule is conserved). In yet a third model, called the dispersive model, all four strands of DNA following replication have a mixture of old and new DNA. Although mechanisms for conservative or dispersive DNA replication are not easy to devise, these models remained possibilities until they were ruled out.
In analyzing the number of different bases in a DNA sample, which result would be consistent with the base-pairing rules?
- A = C
- G = T
- A = G
- A + T = G + T
- A + G = C + T
A + G = C + T
Ex.
In analyzing the number of different bases in a DNA sample, the result that would be consistent with the base-pairing rules is A + G = C + T.
The number of A and T bases must be equal because A pairs with T. For similar reasons, the number of C and G bases is equal. The correct answer is determined by simple addition: if A=T and C=G, then there is only one correct answer.
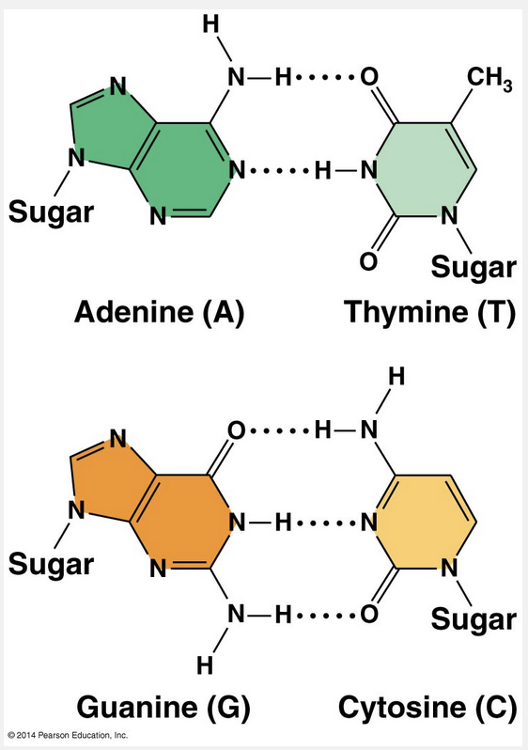
In DNA, the two purines are __________, and the two pyrimidines are __________.
- adenine and guanine; cytosine and thymine
- adenine and cytosine; guanine and thymine
- cytosine and guanine; adenine and thymine
- adenine and thymine; cytosine and guanine
- cytosine and thymine; adenine and guanine
adenine and guanine; cytosine and thymine
Ex.
In DNA, the two purines are adenine and guanine and the two pyrimidines are cytosine and thymine. DNA is composed of four nitrogenous bases.
Guanine and adenine are purines, which have two rings, whereas cytosine and guanine are pyrimidines, which each have a single ring. A helpful mnemonic might be “PUGA” (“PUrines are G and A”).
Chargaff analyzed DNA and found that the numbers of adenine molecules is approximately equal to the numbers of __________ molecules and that the numbers of __________ molecules is approximately equal to the numbers of __________ molecules.
- guanine; thymine; cytosine
- adenine; guanine; guanine
- cytosine; thymine; adenine
- thymine; guanine; cytosine
- cytosine; guanine; thymine
thymine; guanine; cytosine
Ex.
Chargaff analyzed DNA and found that the numbers of adenine molecules is approximately equal to the numbers of thymine molecules and that the numbers of guanine molecules is approximately equal to the numbers of cytosine molecules.
Chargaff noticed a peculiar regularity in the ratios of nucleotide bases. In the DNA of each species he studied, the number of adenines approximately equaled the number of thymines, and the number of guanines approximately equaled the number of cytosines. In sea urchin DNA, for example, Chargaff’s analysis found the four bases to have these percentages: A = 32.8% and T = 32.1%; G = 17.7% and C = 17.3%. (The percentages are not exactly the same because of limitations in Chargaff’s techniques.) These two findings became known as Chargaff’s rules: (1) The base composition of DNA varies among species and (2) For each species, the percentages of A and T bases are roughly equal, and the percentages of G and C bases are roughly equal.
“Guanine; thymine; cytosine” is incorrect because thymine does not base-pair with cytosine; therefore, the ratios would not be approximately equal. “Cytosine; guanine; thymine” is incorrect because adenine does not base-pair with cytosine and guanine does not base-pair with thymine. “Adenine; guanine; guanine” is incorrect because adenine does not base-pair with itself and guanine does not base-pair with itself. “Cytosine; thymine; adenine” is incorrect because adenine does not base-pair with cytosine.
Proteins that are involved in packaging the eukaryotic chromosome into “beads” called __________ are __________.
- a helix; nucleosomes
- chromatids; histones
- histones; nucleosomes
- nucleosomes; histones
- nucleosomes; looped domains
nucleosomes; histones
Ex.
Proteins that are involved in packaging the eukaryotic chromosome into “beads” called nucleosomes are histones.
Proteins called histones are responsible for the first level of DNA packing in chromatin. Although each histone is small—containing only about 100 amino acids—the total mass of histone in chromatin roughly equals the mass of DNA. More than a fifth of a histone’s amino acids are positively charged (lysine or arginine) and therefore bind tightly to the negatively charged DNA. In electron micrographs, unfolded chromatin is 10 nm in diameter (the 10-nm fiber). Such chromatin resembles beads on a string. Each “bead” is a nucleosome, the basic unit of DNA packing; the “string” between beads is called linker DNA. A nucleosome consists of DNA wound twice around a protein core of eight histones.
“Histones; nucleosomes” is incorrect because histones are proteins that package the DNA into nucleosomes. “Chromatids; histones” is incorrect because chromatids are copies of duplicated chromosomes that are visible during metaphase. “A helix; nucleosomes” is incorrect because the DNA double helix is associated with histones forming nucleosomes. “Nucleosomes; looped domains” is incorrect because looped domains are seen in the 300-nm fiber of the condensing DNA.
Who is credited with explaining the structure of the DNA double helix?
- Hershey and Chase
- Watson and Crick
- Jacob and Monod
- Avery, McCarty, and MacLeod
- Griffith
Watson and Crick
Ex.
Watson and Crick are credited with explaining the structure of the DNA double helix.
A correct answer requires recalling key historical points. All answers include people whose discoveries contributed to understanding some aspect of DNA, but not necessarily its structure. Watson and Crick explained the structure of DNA.
Jacob and Monod studied gene expression after the structure of DNA had been described. Avery, McCarty, and MacLeod showed that DNA is the transforming agent in bacteria. Griffith was the first to show that bacterial transformation occurs. Hershey and Chase showed that DNA is the genetic material in certain phages.
A virus that infects bacteria is called a __________, which is made up of the macromolecules __________ and __________.
- Streptococcus; DNA; RNA
- bacteriophage; DNA; protein
- Streptococcus; DNA; protein
- bacteriophage; DNA; RNA
- bacteriophage; RNA; protein
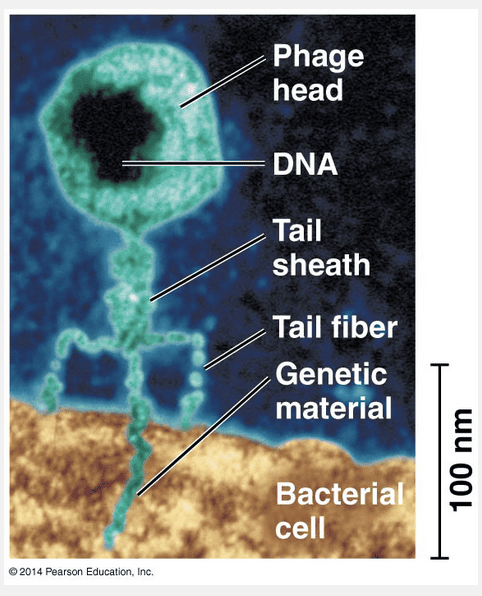
bacteriophage; DNA; protein
Ex.
A virus that infects bacteria is called a bacteriophage, which is made up of the macromolecules DNA and protein.
Additional evidence that DNA is genetic material came from studies of viruses that infect bacteria. These viruses are called bacteriophages (meaning “bacteria-eaters”) or phages for short. Viruses are much simpler than cells and are little more than DNA (or sometimes RNA) enclosed by a protective coat, which is often simply protein. To produce more viruses, a virus must infect a cell and take over the cell’s metabolic machinery.
“Bacteriophage; DNA; RNA” and “bacteriophage; RNA; protein” are incorrect because the macromolecules that make up the bacteriophage are DNA and protein. “Streptococcus; DNA; protein” and “Streptococcus; DNA; RNA” are incorrect because the virus that infects bacteria is a bacteriophage that contains the macromolecules DNA and protein.
The experiments of Meselson and Stahl showed that DNA __________.
- contains complementary base pairing
- codes for the sequence of amino acids in proteins
- replicates in a semiconservative fashion
- is the genetic material
- is composed of nucleotides
replicates in a semiconservative fashion
Ex.
The experiments of Meselson and Stahl showed that DNA replicates in a semiconservative fashion.
Meselson and Stahl used two different isotopes of nitrogen to investigate whether DNA replication is conservative (parental molecule is completely conserved), semi-conservative (each daughter molecule contains one old and one new strand), or dispersive (old and new DNA is mixed in the daughter strands). They found that both strands of the DNA molecule acts as templates for making the new strands.
That DNA is the genetic material, that it is composed of nucleotides, and that it contains complementary base pairing were known prior to their experiments. Meselson and Stahl did not study the role of DNA in coding for the amino acid sequence in protein.
Griffith showed that dead __________ cells __________ living __________ cells into living __________ cells.
- pathogenic; transform; pathogenic; nonpathogenic
- nonpathogenic; transform; pathogenic; nonpathogenic
- pathogenic; transform; nonpathogenic; pathogenic
- nonpathogenic; transform; nonpathogenic; pathogenic
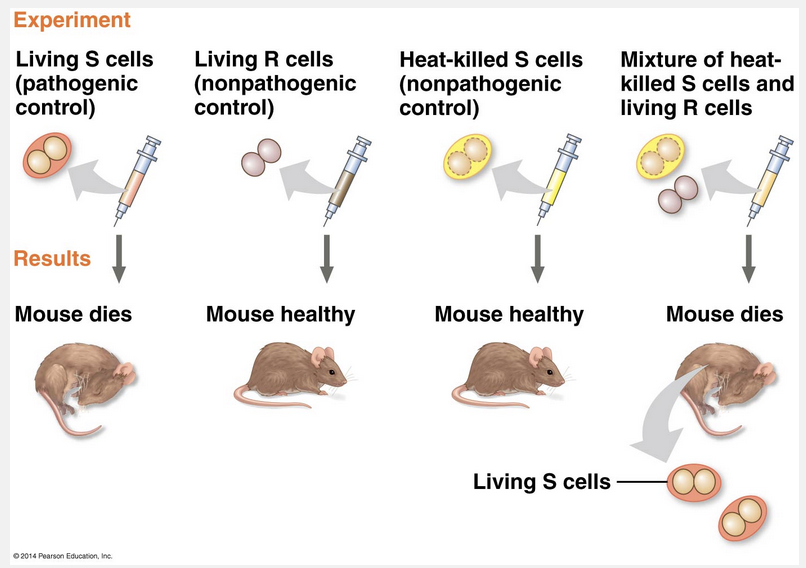
pathogenic; transform; nonpathogenic; pathogenic
Ex.
Griffith showed that dead pathogenic cells transform living nonpathogenic cells into living pathogenic cells.
In 1928, a British medical officer named Frederick Griffith was trying to develop a vaccine against pneumonia. He was studying Streptococcus pneumoniae, a bacterium that causes pneumonia in mammals. Griffith had two strains (varieties) of the bacterium, one pathogenic (disease-causing) and one nonpathogenic (harmless). He was surprised to find that when he killed the pathogenic bacteria with heat and then mixed the cell remains with living bacteria of the nonpathogenic strain, some of the living cells became pathogenic. Furthermore, this newly acquired trait of pathogenicity was then inherited by all the descendants of the transformed bacteria. Apparently, some unidentified chemical component of the dead pathogenic cells caused this heritable change. Griffith called the phenomenon “transformation,” which is now defined as a change in genotype and phenotype due to the assimilation of external DNA by a cell.
“Nonpathogenic; transform; nonpathogenic; pathogenic,” “nonpathogenic; transform; pathogenic; nonpathogenic,” and “pathogenic; transform; pathogenic; nonpathogenic” are incorrect because Griffith used killed pathogenic bacteria and mixed the cell remains with a nonpathogenic living strain and observed that some of the living cells became pathogenic.
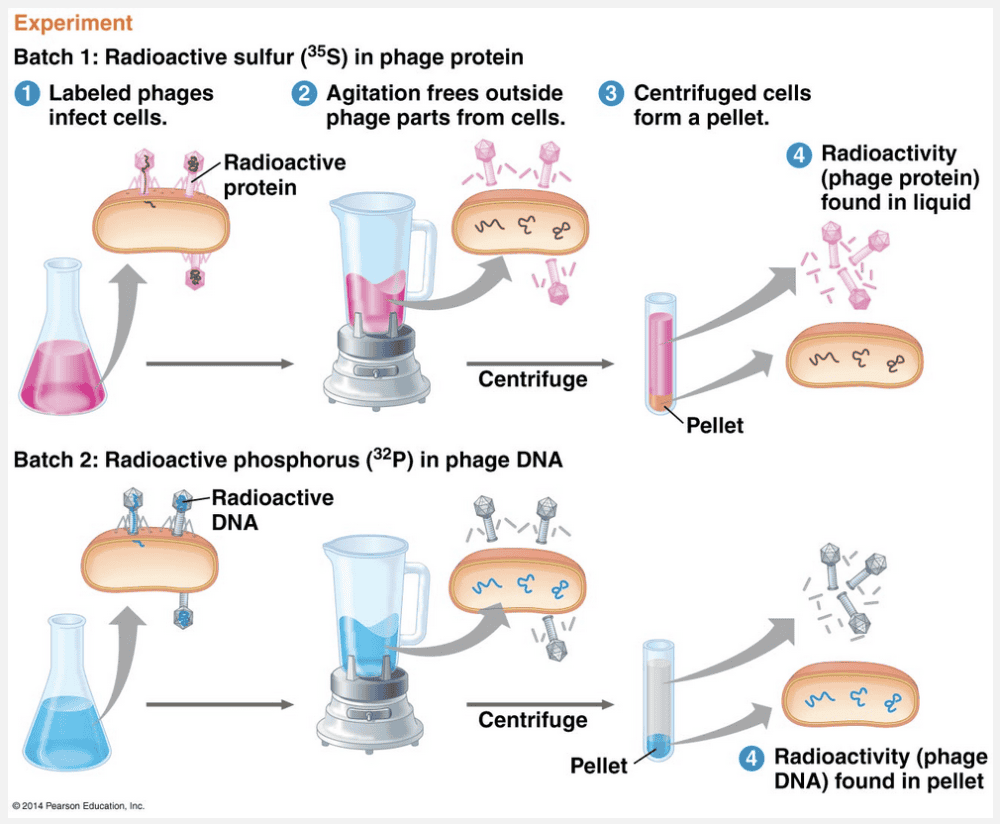
In the famous Hershey and Chase “blender experiment,” radioactive sulfur was used to label __________, and radioactive phosphorus was used to label __________, demonstrating that the genetic material of a bacteriophage is __________.
- protein; DNA; DNA
- protein; DNA; RNA
- DNA; RNA; protein
- RNA; protein; DNA
- DNA; protein; DNA
protein; DNA; DNA
Ex.
In the famous Hershey and Chase “blender experiment,” radioactive sulfur was used to label protein, and radioactive phosphorus was used to label DNA, demonstrating that the genetic material of a bacteriophage is DNA.
Hershey and Chase devised an experiment showing that only one of the two components of T2 actually enters the E. coli cell during infection. In their experiment, they used a radioactive isotope of sulfur to tag protein in one batch of T2 and a radioactive isotope of phosphorus to tag DNA in a second batch. Because protein, but not DNA, contains sulfur, radioactive sulfur atoms were incorporated only into the protein of the phage. In a similar way, the atoms of radioactive phosphorus labeled only the DNA, not the protein, because nearly all the phage’s phosphorus was in its DNA. In the experiment, separate samples of nonradioactive E. coli cells were infected with the protein-labeled and DNA-labeled batches of T2. The researchers then tested the two samples shortly after the onset of infection to see which type of molecule—protein or DNA—had entered the bacterial cells and would therefore be capable of reprogramming them. Hershey and Chase found that the DNA phage entered the host cells but that the protein phage did not. Moreover, when these bacteria were returned to a culture medium and the infection ran its course, the E. coli released phages that contained some radioactive phosphorus. This result further showed that the DNA inside the cell plays an ongoing role during the infection process. Hershey and Chase concluded that the DNA injected by the phage must be the molecule carrying the genetic information that makes the cells produce new viral DNA and proteins.
“DNA; protein; DNA,” “RNA; protein; DNA,” and “DNA; RNA; protein” are incorrect because sulfur is found only in proteins and phosphorus is found only in nucleic acids. “Protein; DNA; RNA” is incorrect because this experiment showed that the genetic material was DNA.
X-ray diffraction images produced by __________ showed that DNA is a __________.
- Franklin; double helix
- Crick; double helix
- Wilkins; triple helix
- Pauling; triple helix
- Watson; double helix
Franklin; double helix
Ex.
X-ray diffraction images produced by Franklin showed that DNA is a double helix.
While visiting the laboratory of Maurice Wilkins, James Watson saw an X-ray diffraction image of DNA produced by Wilkins’s accomplished colleague, Rosalind Franklin. Images produced by X-ray crystallography are not actually pictures of molecules. Rather, the spots and smudges in the figure below were produced by X-rays that were diffracted (deflected) as they passed through aligned fibers of purified DNA. Watson was familiar with the type of X-ray diffraction pattern that helical molecules produce, and an examination of the photo that Wilkins showed him confirmed that DNA is helical in shape.
“Watson; double helix,” “Wilkins; triple helix,” “Pauling; triple helix,” and “Crick; double helix” are incorrect because the X-ray diffraction images were work done by Rosalind Franklin that allowed Watson and Crick to deduce that DNA is a double helix.
The information in DNA is contained in __________.
- the variation in the structure of nucleotides that make up the DNA molecule
- the types of sugars used in making the DNA molecule
- All of the listed responses are correct
- the sequence of nucleotides along the length of the two strands of the DNA molecule
- the sequence of amino acids that makes up the DNA molecule
the sequence of nucleotides along the length of the two strands of the DNA molecule
Ex.
The information in DNA is contained in the sequence of nucleotides along the length of the two strands of the DNA molecule.
“Information in DNA” refers to the hereditary program that directs the development and, to some extent, expression of an organism’s traits. It is carried in the sequence of nucleotides along the length of the two strands of the DNA molecule. The structure of nucleotides does not change, nor does the type of sugar vary: It is always deoxyribose. DNA is not composed of amino acids.
Which description of DNA replication is correct?
- Helicases separate the two strands of the double helix, and DNA polymerases then construct two new strands using each of the original strands as templates.
- Ligase assembles single-stranded codons, then polymerase knits these codons together into a DNA strand.
- The two strands separate, and each one receives a complementary strand of RNA. Then this RNA serves as a template for the assembly of many new strands of DNA.
- Ligase separates the two strands of the DNA double helix. Then, DNA polymerase synthesizes the leading strand and primase synthesizes the lagging strand.
- The two strands of DNA separate, and restriction enzymes cut up one strand. Then, the DNA polymerase synthesizes two new strands out of the old ones.
Helicases separate the two strands of the double helix, and DNA polymerases then construct two new strands using each of the original strands as templates.
Ex.
Helicases separate the two strands of the double helix, and DNA polymerases then construct two new strands using each of the original strands as templates.
This is the correct description of DNA replication. Only one answer choice includes correct roles for each enzyme and states the events in DNA synthesis correctly. Helicases separate the two strands of the double helix, and DNA polymerases construct two new strands using each of the original strands as templates.
Ligases do not assemble codons. The DNA molecule is not destroyed during replication. RNA is not the template for the assembly of new DNA, although RNA serves as a primer to initiate the process. DNA polymerase catalyzes the synthesis of both leading and lagging strands.
What is the major difference between bacterial chromosomes and eukaryotic chromosomes?
- There is no difference between bacterial and eukaryotic chromosomes.
- Eukaryotes have a single circular chromosome whereas bacteria have several linear chromosomes.
- Bacterial chromosomes have much more protein associated with the DNA than eukaryotes.
- Bacteria have a single circular chromosome whereas eukaryotes have several linear chromosomes.
- The DNA of bacterial chromosomes has a slightly different structure.
Bacteria have a single circular chromosome whereas eukaryotes have several linear chromosomes.
Ex.
The major difference between bacterial chromosomes and eukaryotic chromosomes is that bacteria have a single circular chromosome whereas eukaryotes have several linear chromosomes.
The DNA of bacterial and eukaryotic chromosomes has the same molecular structure. Bacteria have a single circular chromosome, whereas eukaryotes have several linear chromosomes. Bacterial chromosomes have considerably less protein associated with their DNA than the chromosomes of eukaryotes, and these and other factors result in important structural differences between the DNA of eukaryotes and prokaryotes.
The unwinding of DNA at the replication fork causes twisting and strain in the DNA ahead of the fork, which is relieved by an enzyme called __________.
- relievase
- primase
- topoisomerase
- ribosomes
- ligase
topoisomerase
Ex.
The unwinding of DNA at the replication fork causes twisting and strain in the DNA ahead of the fork, which is relieved by an enzyme called topoisomerase.
To keep the names and functions of these enzymes straight, it is helpful to construct a table with the names of the enzymes in the first column and their functions in the second column. Topoisomerase is the enzyme that relieves strain on the DNA molecule as it unwinds by breaking, swiveling, and rejoining the strands.
Primase synthesizes the RNA primer. Relievase does not exist. Ligase links Okazaki fragments together on the lagging strand. Ribosomes are not enzymes at all, but are ribosomal RNA-protein complexes that are the site of protein synthesis.
Telomeres are __________.
- repeating noncoding sequences at the ends of circular bacterial chromosomes
- nonrepeating noncoding sequences at the ends of linear eukaryotic chromosomes
- repeating noncoding sequences at the ends of linear eukaryotic chromosomes
- None of the listed responses is correct.
- nonrepeating noncoding sequences at the ends of circular bacterial chromosomes
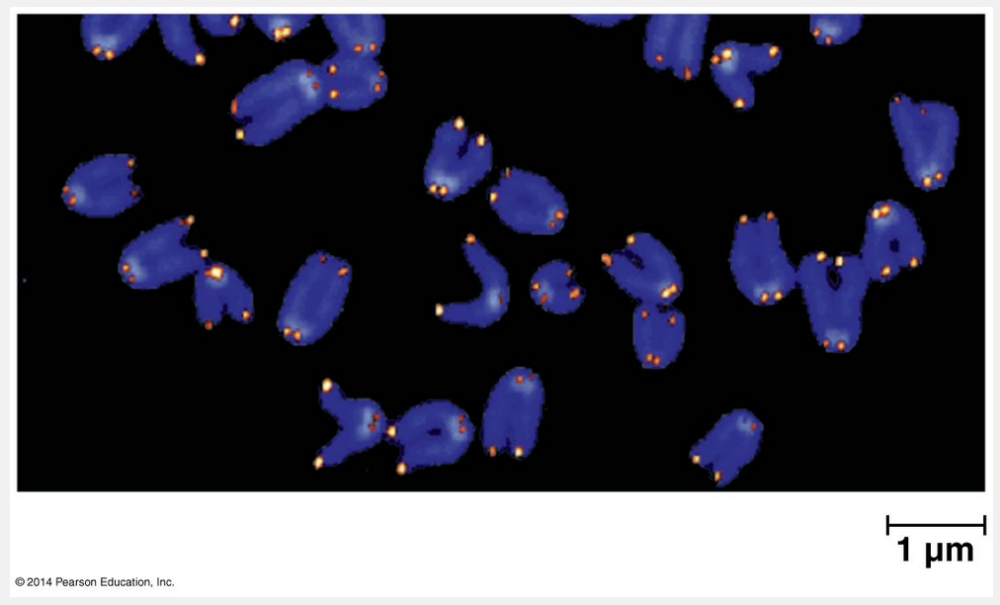
repeating noncoding sequences at the ends of linear eukaryotic chromosomes
Ex.
Telomeres are repeating noncoding sequences at the ends of linear eukaryotic chromosomes.
Eukaryotic chromosomal DNA molecules have special nucleotide sequences at their ends called telomeres. Telomeres do not contain genes; instead, their DNA typically consists of multiple repetitions of one short nucleotide sequence. In each human telomere, for example, the six-nucleotide sequence TTAGGG is repeated between 100 and 1,000 times. Telomeres have two protective functions. First, specific proteins associated with telomeric DNA prevent the staggered ends of the daughter molecule from activating the cell’s systems for monitoring DNA damage. (Staggered ends of a DNA molecule, which often result from double-strand breaks, can trigger signal transduction pathways leading to cell cycle arrest or cell death.) Second, telomeric DNA acts as a kind of buffer zone that provides some protection against the organism’s genes shortening, similar to how the plastic-wrapped ends of a shoelace slow its unraveling. However, telomeres do not prevent the erosion of genes near the ends of chromosomes; they merely postpone it.
“Repeating noncoding sequences at the ends of circular bacterial chromosomes” and “nonrepeating noncoding sequences at the ends of circular bacterial chromosomes” are incorrect because the bacterial chromosome is circular and does not have telomeric ends. “Nonrepeating noncoding sequences at the ends of linear eukaryotic chromosomes” is incorrect because telomeres are repeating noncoding sequences.
Why were many of the early experiments on DNA carried out on viruses and bacteria?
- They have short generation times.
- They have relatively small genomes.
- They can interact with each other.
- All of the responses are true.
- Their chromosomes have a simpler structure.
All of the responses are true.
Ex.
All of the responses are true.
Remember to read all the answer choices before making your selection. In this case, all answers are correct. Viruses and bacteria offer several advantages to experimenters: They have short generation times, have small genomes relative to eukaryotes, have chromosomes with a simpler structure than eukaryotes, and can interact with each other in ways that provide information about their function.
DNA replication begins at a site called the origin of replication, forming a bubble, which is followed by a __________, where parental strands are unwound by __________.
- replication fork; RNA primers
- replication Y; topoisomerases
- replication Y; helicases
- replication fork; topoisomerases
- replication fork; helicases
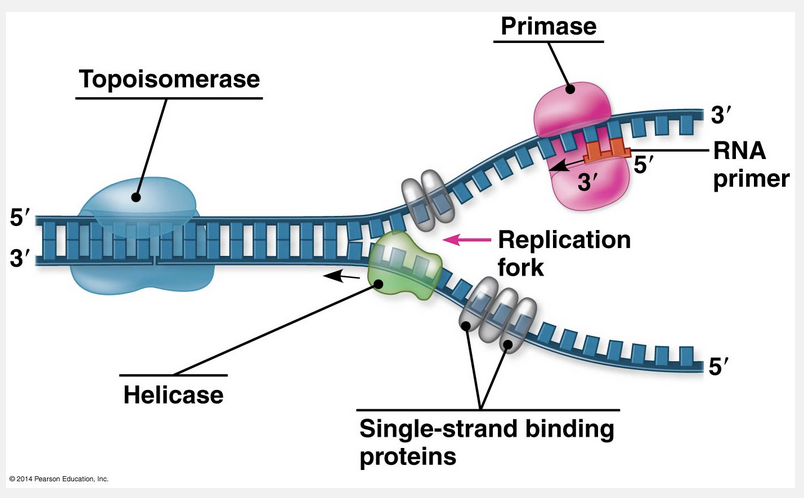
replication fork; helicases
Ex.
DNA replication begins at a site called the origin of replication, forming a bubble, which is followed by a replication fork, where parental strands are unwound by helicases.
The replication of a chromosome begins at particular sites called origins of replication, which are short stretches of DNA having a specific sequence of nucleotides. Proteins that initiate DNA replication recognize this sequence and attach to the DNA, separating the two strands and opening up a replication “bubble.” Replication of DNA then proceeds in both directions until the entire molecule is copied. At each end of a replication bubble is a replication fork, a Y-shaped region where the parental strands of DNA are unwound. Several kinds of proteins participate in the unwinding. Helicases are enzymes that untwist the double helix at the replication forks, separating the two parental strands and making them available as template strands. After the parental strands separate, single-strand binding proteins bind to the unpaired DNA strands, keeping them from pairing up. The untwisting of the double helix causes tighter twisting and strain ahead of the replication fork. Topoisomerases help relieve this strain by breaking, swiveling, and rejoining DNA strands.
The 5ꞌ end of a DNA strand always has a free __________ group while the 3ꞌ end always has a free __________ group.
- phosphate; acidic
- phosphate; amine
- amine; phosphate
- phosphate; hydroxyl
- hydroxyl; phosphate
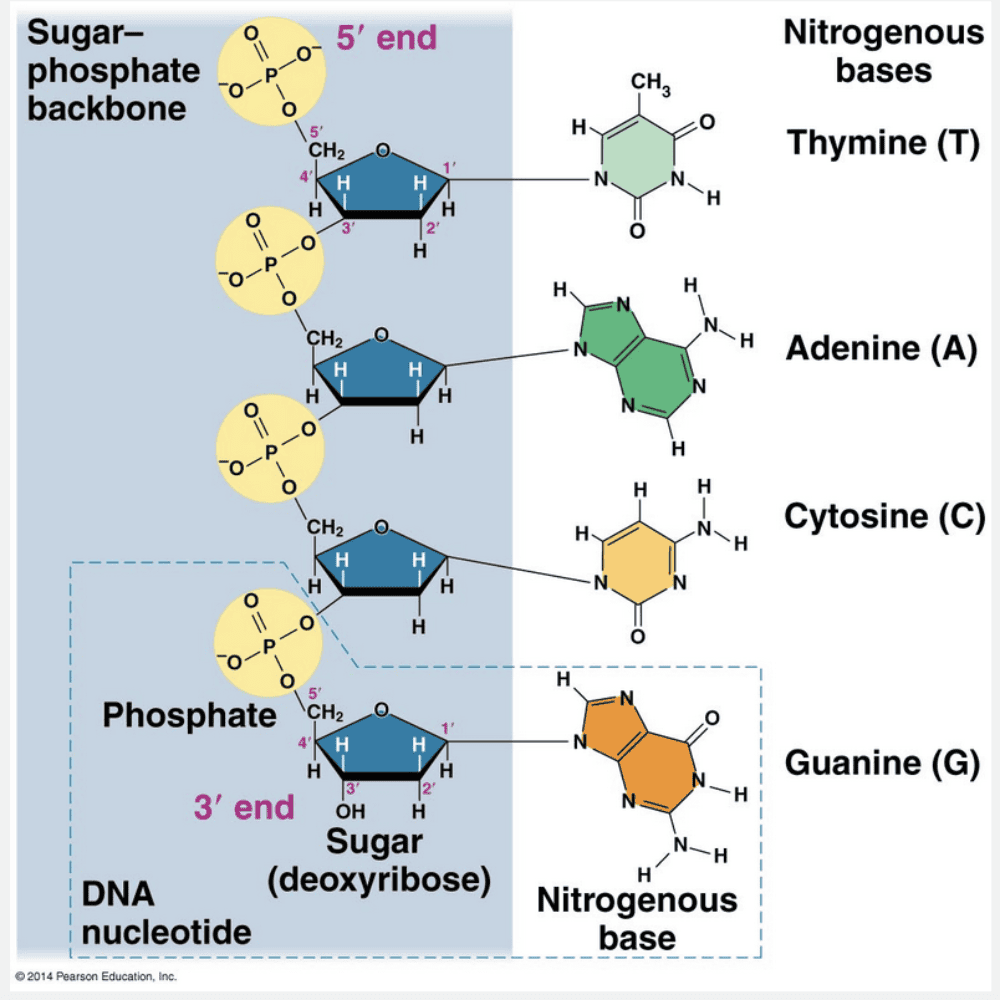
phosphate; hydroxyl
Ex.
The 5ꞌ end of a DNA strand always has a free phosphate group while the 3ꞌ end always has a free hydroxyl group.
In the Watson and Crick model of DNA, the two sugar-phosphate backbones are antiparallel—that is, their subunits run in opposite directions (see figure below). The overall arrangement is similar to that of a rope ladder with rigid rungs. The side ropes represent the sugar-phosphate backbones, and the rungs represent pairs of nitrogenous bases. The two free ends of the polymer are distinctly different from each other. That is, one end has a phosphate attached to the 5ꞌ carbon, called the 5ꞌ end, while a hydroxyl group is attached to the 3ꞌ carbon, called the 3ꞌ end.
“Hydroxyl; phosphate,” “phosphate; amine,” “amine; phosphate,” and ”phosphate; acidic” are incorrect because in DNA, the 5ꞌ end always has a free phosphate group, and the 3ꞌ end always has a free hydroxyl group.
Which of the following components is required for DNA replication?
- RNA primer
- Transfer RNA
- Proteases
- Sucrases
- Ribosomes
RNA primer
Ex.
RNA primer is required for DNA replication.
DNA cannot initiate its own synthesis: It requires an RNA primer, which is a short chain of 5-10 nucleotides that is base-paired to the original DNA strand.
Ribosomes are the site of protein synthesis. Transfer RNA is necessary for the synthesis of polypeptides. Proteases are enzymes that digest polypeptides. Sucrase is an enzyme that breaks down the disaccharide sucrose into its component monosaccharides glucose and fructose.